Create an Audio Transcript with Amazon Transcribe, API Gateway, Lambda, S3 and Terraform
Sample using AWS Lambda, API Gateway, S3, Amazon Transcribe, and Terraform
Y
Software Engineer.
Search for a command to run...
Sample using AWS Lambda, API Gateway, S3, Amazon Transcribe, and Terraform
Software Engineer.
No comments yet. Be the first to comment.
All the ChatGPT APIs in one Swagger.

ChatGPT, AWS Lambda, Java

AWS Sample using Lambda, SNS, Event Bridge, Terraform
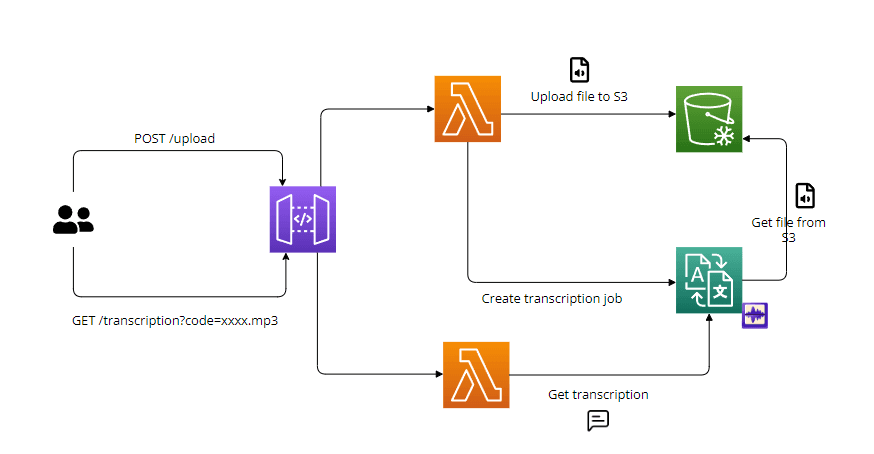
Based on this AWS tutorial "Create an Audio Transcript with Amazon Transcribe" we will create all the processes using AWS API Gateway, Lambda, Amazon Transcribe and S3, all with Terraform.
As the transcription service can take a couple of seconds to extract the speech from the audio, we need two endpoints:
The first one is a POST endpoint that triggers a lambda which will upload the audio file to an S3 bucket and trigger a transcript job, it looks like this https://xxxxxxx.execute-api.eu-west-1.amazonaws.com/dev/upload
The second one is a GET endpoint to get the result of transcription, it looks like this https://xxxxxxx.execute-api.eu-west-1.amazonaws.com/dev/transcription?code=f55c863e-60b2-4f64-9ed2-bd4b0afe0168.mp3
The terraform code of these two endpoints:
resource "aws_apigatewayv2_api" "http_api" {
name = "transcribe_api"
protocol_type = "HTTP"
description = "HTTP API to send audio files to Lambda"
cors_configuration {
allow_credentials = false
allow_headers = []
allow_methods = ["GET", "POST"]
allow_origins = ["*"]
expose_headers = []
max_age = 0
}
}
# Upload audio endpoint
resource "aws_apigatewayv2_integration" "api_upload" {
api_id = aws_apigatewayv2_api.http_api.id
integration_uri = aws_lambda_function.upload_audit_lambda.invoke_arn
integration_type = "AWS_PROXY"
}
resource "aws_apigatewayv2_route" "api_upload" {
api_id = aws_apigatewayv2_api.http_api.id
route_key = "POST /upload"
target = "integrations/${aws_apigatewayv2_integration.api_upload.id}"
}
# Get transcription endpoint
resource "aws_apigatewayv2_integration" "api_transcription" {
api_id = aws_apigatewayv2_api.http_api.id
integration_uri = aws_lambda_function.get_transcription_lambda.invoke_arn
integration_type = "AWS_PROXY"
}
resource "aws_apigatewayv2_route" "api_transcription" {
api_id = aws_apigatewayv2_api.http_api.id
route_key = "GET /transcription"
target = "integrations/${aws_apigatewayv2_integration.api_transcription.id}"
}
# Stage
resource "aws_apigatewayv2_stage" "api_stage_dev" {
api_id = aws_apigatewayv2_api.http_api.id
name = "dev"
auto_deploy = true
depends_on = [aws_apigatewayv2_integration.api_upload]
}
resource "aws_s3_bucket" "transcript_bucket" {
bucket_prefix = "transcript-bucket-"
force_destroy = true
}
import base64
import boto3
import json
import os
import uuid
s3_client = boto3.client('s3')
transcribe = boto3.client('transcribe')
bucket_name = os.environ['S3_BUCKET_NAME']
def lambda_handler(event, context):
body = event['body']
body_bytes = bytes(body, 'utf-8')
body_base64 = base64.b64decode(body_bytes)
name = str(uuid.uuid4()) + '.mp3'
s3_client.put_object(Bucket=bucket_name, Body=body_base64, Key=name)
start_transcript_job(name)
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json"
},
"body": json.dumps({
"code ": name
})
}
def start_transcript_job(key):
job_name = key
job_uri = f"s3://{bucket_name}/{key}"
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='mp3',
LanguageCode='en-US'
)
This lambda will be triggered by the first POST endpoint mentioned before, it will then:
Extract the audio file from the body of the request event['body'].
Upload the file to S3 with a UUID, for example 0fc6f6de-0634-4a97-9734-b005f5cb1595.mp3
Start a new transcript job
and finally, return the name of the user so that it can be used to get the transcription with another endpoint.
# Lambda
resource "aws_lambda_permission" "upload_audit_lambda_permission" {
statement_id = "AllowExecutionFromAPIGateway"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.upload_audit_lambda.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.http_api.execution_arn}/*"
}
resource "aws_lambda_function" "upload_audit_lambda" {
filename = local.upload_audio_lambda_file_name
function_name = local.upload_audio_function_name
role = aws_iam_role.upload_audio_role.arn
handler = "lambda_upload_audio.lambda_handler"
runtime = "python3.8"
timeout = 25
source_code_hash = filebase64sha256(local.upload_audio_lambda_file_name)
environment {
variables = {
S3_BUCKET_NAME = aws_s3_bucket.transcript_bucket.bucket
}
}
}
resource "aws_iam_role" "upload_audio_role" {
name = "${local.upload_audio_function_name}_role"
assume_role_policy = <<POLICY
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
POLICY
}
resource "aws_iam_policy" "upload_audit_lambda_policy" {
name = "${local.upload_audio_function_name}-policy"
description = "Policy for ${local.upload_audio_function_name}"
policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateLogGroup"
],
"Resource" : "arn:aws:logs:*:*:*"
},
{
"Effect" : "Allow",
"Action" : ["s3:*"],
"Resource" : "${aws_s3_bucket.transcript_bucket.arn}/*"
},
{
"Action" : ["transcribe:*"],
"Resource" : "*",
"Effect" : "Allow"
}
]
})
}
resource "aws_iam_role_policy_attachment" "upload_audio_role_policy_attachment" {
role = aws_iam_role.upload_audio_role.name
policy_arn = aws_iam_policy.upload_audit_lambda_policy.arn
}
locals {
upload_audio_function_name = "Upload_Audio_Lambda"
upload_audio_lambda_file_name = "lambda_upload_audio.zip"
}
import boto3
import json
import urllib.request
transcribe = boto3.client('transcribe')
def lambda_handler(event, context):
job_name = event['queryStringParameters']['code']
transcript = get_transcription(job_name)
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/html"
},
"body": transcript
}
def get_transcription(job_name):
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
s3_url = status['TranscriptionJob']['Transcript']['TranscriptFileUri']
with urllib.request.urlopen(s3_url) as url:
response = url.read()
json_response = json.loads(response.decode('utf-8'))
return json_response['results']['transcripts'][0]['transcript']
else:
return 'Code not exist, or transcription result not ready.'
This lambda will be triggered by the second GET endpoint mentioned before, it will then:
Extract the job code, for example f55c863e-60b2-4f64-9ed2-bd4b0afe0168.mp3
Make a get_transcription_job, if the status is COMPLETE it simply returns the transcription result in the body.
# Lambda
resource "aws_lambda_permission" "get_transcription_lambda_permission" {
statement_id = "AllowExecutionFromAPIGateway"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.get_transcription_lambda.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.http_api.execution_arn}/*"
}
resource "aws_lambda_function" "get_transcription_lambda" {
filename = local.transcription_lambda_file_name
function_name = local.transcription_function_name
role = aws_iam_role.upload_audio_role.arn
handler = "lambda_get_transcription.lambda_handler"
runtime = "python3.8"
timeout = 25
source_code_hash = filebase64sha256(local.transcription_lambda_file_name)
}
resource "aws_iam_role" "transcription_role" {
name = "${local.transcription_function_name}_role"
assume_role_policy = <<POLICY
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
POLICY
}
resource "aws_iam_policy" "transcription_lambda_policy" {
name = "${local.transcription_function_name}-policy"
description = "Policy for ${local.upload_audio_function_name}"
policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateLogGroup"
],
"Resource" : "arn:aws:logs:*:*:*"
},
{
"Action" : ["transcribe:*"],
"Resource" : "*",
"Effect" : "Allow"
}
]
})
}
resource "aws_iam_role_policy_attachment" "transcription_role_policy_attachment" {
role = aws_iam_role.transcription_role.name
policy_arn = aws_iam_policy.transcription_lambda_policy.arn
}
locals {
transcription_function_name = "Get_Transcription_Lambda"
transcription_lambda_file_name = "lambda_get_transcription.zip"
}
To run all this, just follow these steps:
$ git clone https://github.com/laidani/Create-an-Audio-Transcript-with-Amazon-Transcribe-API-Gateway-Lambda-and-Terraform
$ cd Create-an-Audio-Transcript-with-Amazon-Transcribe-API-Gateway-Lambda-and-Terraform
$ terraform init
$ terraform apply --auto-approve
In the end, you will get the API URL

Now you can use postman for example to upload an audio file:
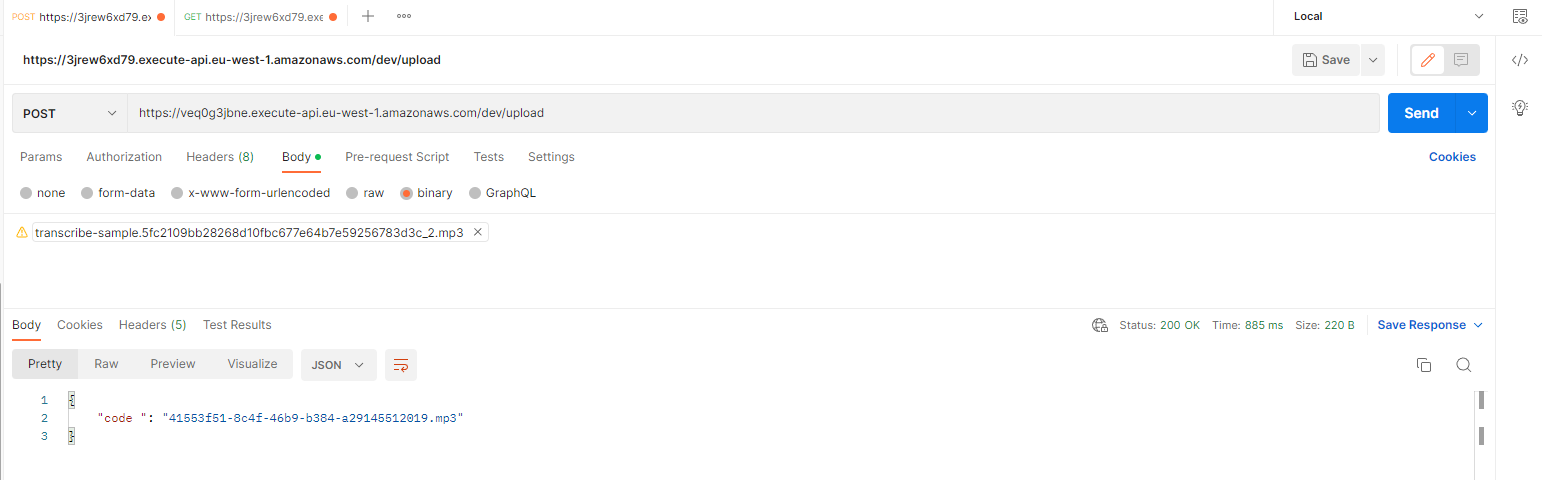
And in a few seconds, you can call the GET transcription endpoint
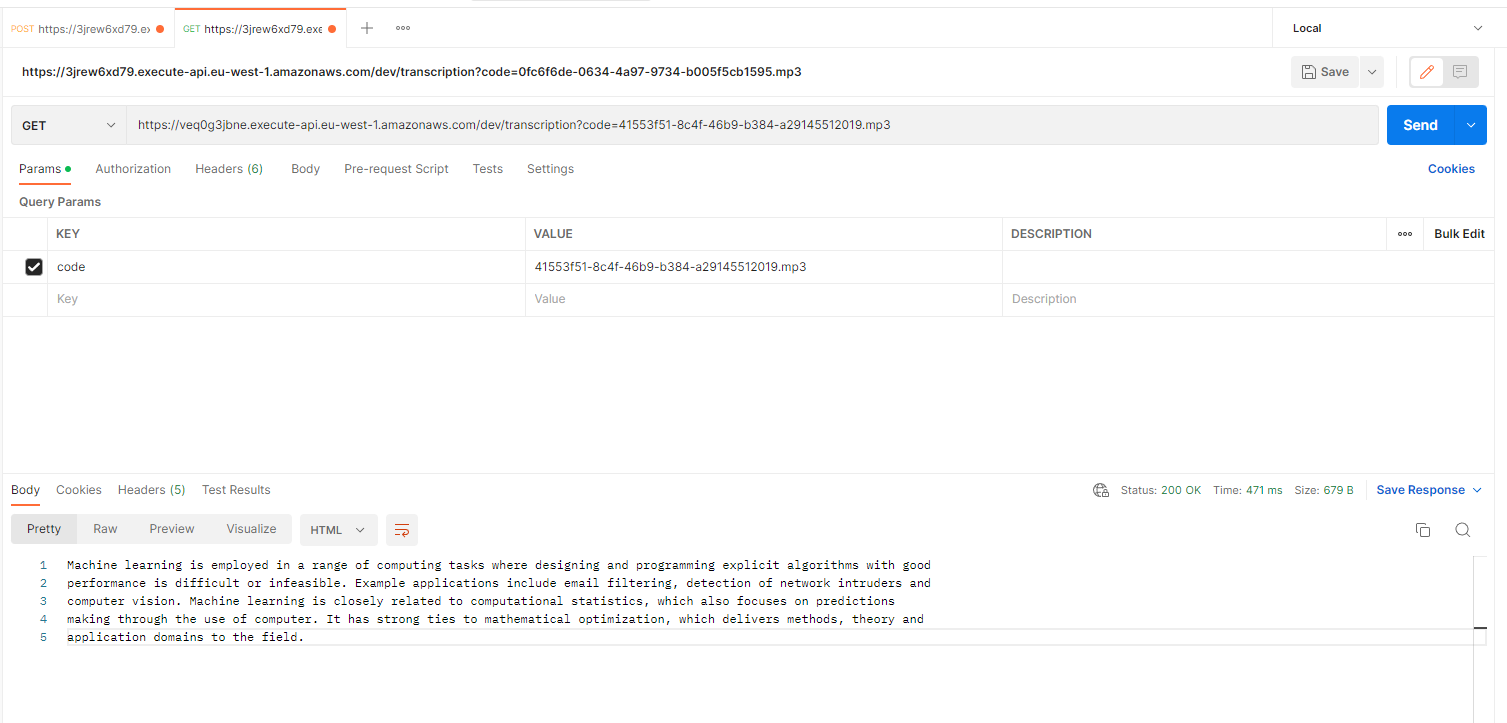
To destroy everything you just execute this command:
terraform apply --destroy --auto-approve
You can find all the code written in this tutorial at https://github.com/laidani/Create-an-Audio-Transcript-with-Amazon-Transcribe-API-Gateway-Lambda-and-Terraform
Enjoy :)